Sogni is a platform where your creativity takes center stage, powered by a revolutionary decentralized Supernet. Built on the collective contributions of real artists, creators, and visionaries, the Supernet combines cutting-edge technology with the unique touch of human imagination.
Whether you’re crafting your vision with our tools or sharing your computing power to support others, Sogni celebrates individuality, fuels collaboration, and rewards creativity. Join us to unlock your potential and be part of a thriving creative community that values privacy, freedom, and the transformative power of self-expression.
Whether you’re crafting your vision with our tools or sharing your computing power to support others, Sogni celebrates individuality, fuels collaboration, and rewards creativity. Join us to unlock your potential and be part of a thriving creative community that values privacy, freedom, and the transformative power of self-expression.
Take Control of Your Creative Journey
Discover Creative AI Tools powered by the Sogni Supernet.



Supernet
A Purpose-Built DePIN Protocol for Creative AI
For Artists
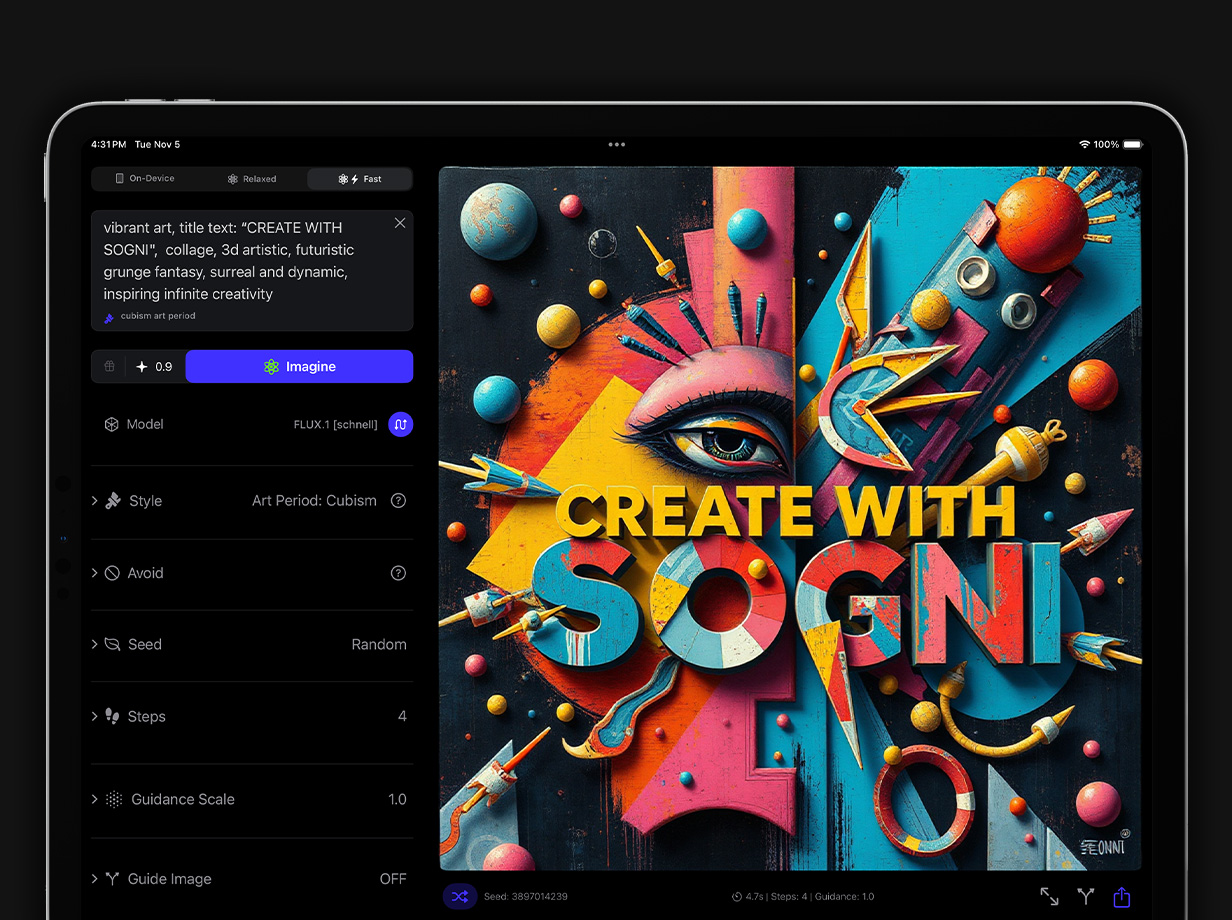
Boost Creativity with 176x Faster Speeds
Unlock your creativity, amplify processing, and speed up creation—all powered by the shared compute power of the Sogni Supernet.
Learn MoreFor Workers
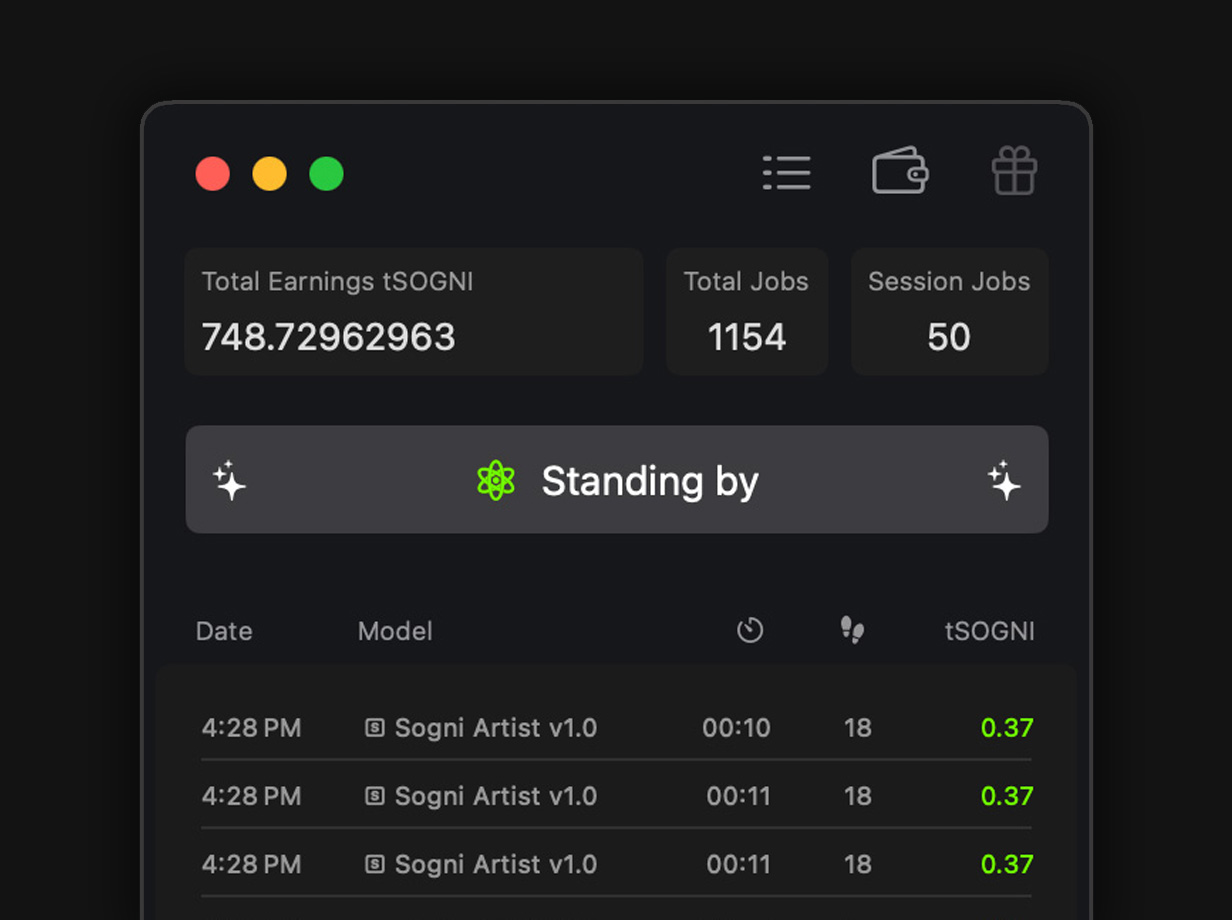
Share Your Compute and Earn
Simply connect to the Sogni Supernet and share your idle computing power with the community. Earn Sogni Tokens as a reward.
Learn MoreFor Developers
Build your Apps with the Sogni SDK
Integrate the power of the Sogni Supernet within your own apps using our Sogni SDK - available for TypeScript and Javascript Projects.
Learn More